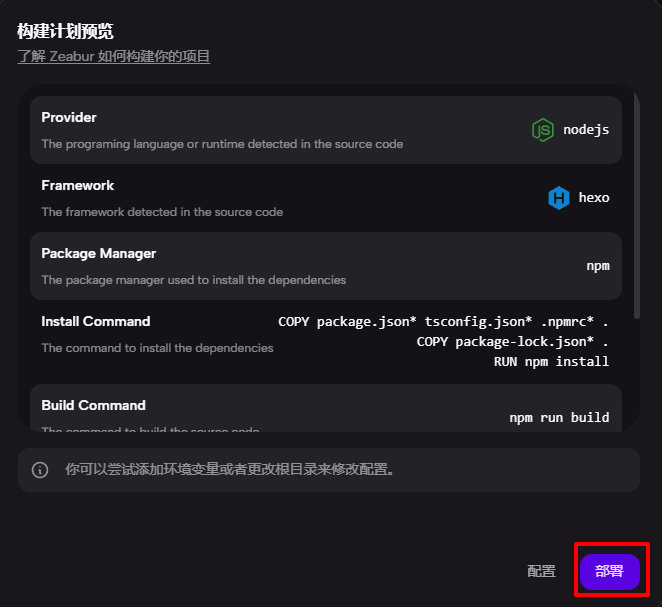
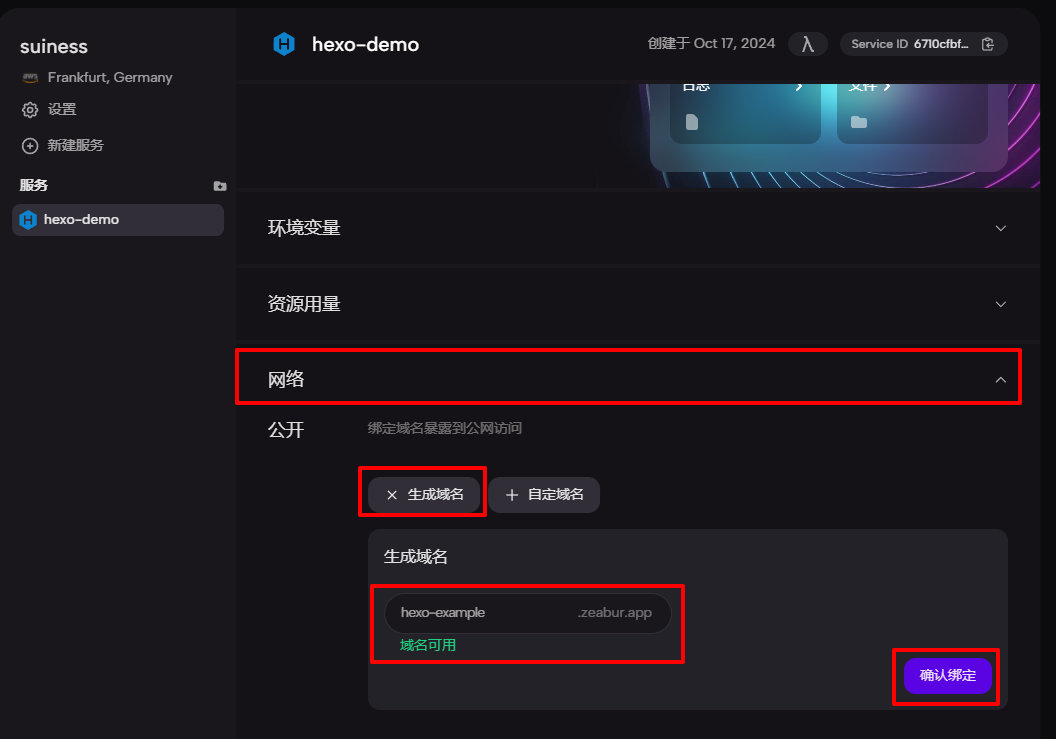
OpenAI
o1-preview
发布于2024年9月13日,o1模型标志着 OpenAI 以在推理能力上的重大进展,相比较之前的GPT-4o,o1-preview在多个方面表现得更加出色,尤其是在编写代码和解决复杂问题的能力上,通过采用全新的优化算法和专门定制的新训练数据集,使得模型在准确性和推理能力上有了显著提升。
o1-mini
与o1-preview同时推出,是o1系列中的小尺寸版,价格比o1-preview便宜80%,虽然存在使用次数的限制,但其在生成和调试复杂代码方面表现出色,特别适合开发人员使用。
gpt-4o-2015-05-13
2024年5月13日, OpenAI 正式发布其大模型新版本 GPT-4o,“o”代表Omni,即全能的意思,凸显了其多功能的特性,从多模态端到端实时推理,无需转换,响应延迟大幅缩短。
gpt-4o
GPT-4o可以将文本、音频、图像和视频的任意组合作为输入,并将文本、音频和图像的任意组合作为输出;可以在最短232毫秒,平均320毫秒的时间,对音频做出响应,这与人类在对话中的响应时间相似。
gpt-4o-mini-2024-07-18
于2024年7月18日推出,该模型是GPT-4o的一个分支,其在保留了GPT-4功能的同时,体积上比GPT-4o等大模型要小得多,成本价格上也更加便宜。
gpt-4-plus
是GPT-4的升级版,在GPT-4的基础上升级了一些功能,包括更精确的文本表示、更先进的情感分析和更高的语义理解能力等,在自然语言理解和生成方面的表现更加出色。
gpt-4o-2024-08-06
于2024年8月6日上线,是多模态模型GPT-4o的更新版,在其API中引入一项突破性功能——结构化输出,确保了模型生成的输出能够完全符合开发人员提供的JSON架构,从而显著提升了API的可靠性和应用的精确度。
chatgpt-4o-latest
于2024年8月15日发布,是GPT-4o的最新版本,在编码、指令遵循和硬提示方面都有显著提高,最大支持128K上下文输出,最大输出Tokens达16K,在推理方面与GPT-4o相比有较大提升。
gpt-4-turbo
于2024年4月正式推出,模型功能更强大、更便宜,并支持128K上下文窗口;平台中新的多模态功能,包括视觉、图像创建和文本转语音;知识库更新上,其现实世界知识截止时间现在是2023年4月;价格上输入代币比GPT-4便宜3倍,输出代币便宜2倍。
gpt-4-turbo-preview
GPT-4-Turbo预览模型,在2023年11月6日亮相,之后有0125版本更新,其不仅在性能上有所提升,还修复了一个影响非英文UTF-8生成的漏洞,增加了模型的稳定性和多语言支持。
gpt-3.5-turbo-0125
GPT-3.5-turbo的最新模型,在按请求格式回应时具有更高的准确性,并修复了一个错误,该错误导致非英语语言函数调用时出现文本编码问题,在稳定性和准确性都提高的同时,gpt-3.5-turbo-0125价格相比之前也降低了。
gpt-4
于2023年3月14日由OpenAI正式发布,它是GPT系列模型的第四代,具有更强的语言理解和生成能力、多模态处理能力、更大的模型规模、改进的安全性和伦理性等,可应用于如对话系统、内容生成、代码编写、数据分析、教育和研究等各种领域。
Gemini
gemini-1.5-pro-002
谷歌发布于2024年9月25日,相比其他1.5系列模型的其他版本,新版的1.5 Pro整体素质提高,数学、长上下文和视觉上有大幅增加,能够更好地理解更加复杂和具有细微差异的指令,价格上降低>50%,速率限制提高了约3倍,输出速度提高2倍,延迟降低3倍。
gemini-1.5-flash-002
与gemini-1.5-pro-002共同发布,虽然是一个较为轻量的模型,但其在多模态推理能力方面依然表现出色,擅长摘要制作、聊天应用、提供图说和视频字幕,以及从长篇文件和表格中提取数据等任务,且在响应速度方面有了极大的改进。
gemini-1.5-pro
第一代模型由谷歌发布于2024年2月15日,为Gemini-1.0-Pro的升级版本,支持超长上下文内容,能够稳定处理高达100万token(相当于1小时的视频、11小时的音频、超过3万行代码或70万个单词);支持多模态输入,能够分析、总结、处理多种形式,包括图片、文档、视频和音频。
gemini-1.5-pro-0801
是gemini-1.5-pro的实验版本,擅长多语言任务,并在数学、复杂提示和编码等技术领域表现出色,其另一个突出特点是其高达 200 万个token的扩展上下文窗口,已经远远超过了市面上许多的AI模型。
gemini-1.5-flash-001
谷歌于5月15日推出,1.5 Flash是通过API提供的速度最快的Gemini模型,在具备突破性的长文本能力的情况下,针对大规模地处理高容量、高频次任务进行了优化,在总结摘要、聊天应用、图像和视频字幕生成以及从长文档和表格中提取数据等方面表现出色。
ANTHROPIC
claude-3.5-soonet-20241022
Anthropic最新推出的升级版,各项能力全面胜过之前版本,其中代码能力提升显著,能够根据用户指令移动光标、点击相应位置以及通过虚拟键盘输入信息,模仿人类与计算机的交互方式。
claude-3.5-sonnet-20240620
Anthropic公司于2024年6月20日发布的LLM大语言模型,属于Claude3.5系列模型中的先遣版本,在理解细微差异、幽默感和复杂指令方面表现得更为出色,书写风格也更自然、更具亲和力,擅长解释图表、图形。
claude-3-opus
Opus是Claude3系列中最先进的模型,在高度复杂的任务上表现出了市场上最好的性能,它能够轻松应对各种开放式提示和未知场景,并以出色的流畅度和人类般的理解能力完成任务。
claude-3-haiku
是Anthropic速度最快、体积最小的模型,能够提供几乎即时的响应能力,可以极快地解答简单的问题和响应请求,Haiku的定价是每百万token输入0.25美元、输出1.25 美元,相当便宜。
Perplexity AI
pplx-8b-online
由Perplexity AI公司推出,是一款基于大语言模型(LLM)的在线模型,它利用实时互联网数据提供即时、精确的查询响应,通过API提供,能够实现对查询的即时响应,标志着首次通过API公开访问在线LLMs。
pplx-70b-online
基于Llama2-70B基础模型构建,这款在线模型的主要特点是能够实时访问互联网数据,从而提供最新的信息,它通过Perplexity Labs的内部搜索基础设施,优先访问高质量和权威的网站,并采用先进的排名机制来实时呈现相关和可靠的信息片段。
智谱AI
GLM-4
GLM-4是智谱AI于2024年1月16日发布的基座大模型,可以支持128k的上下文窗口长度,单次提示词可以处理的文本可以达到300页,同时在多模态能力方面,文生图和多模态理解都得到了增强。
GLM-4-Long
专为处理超长文本和记忆型任务设计的模型,支持超长输入,上下文长度最高为1M,约150-200万字,具备长文本推理能力,处理百万字文本响应时间可控,是处理大规模文本数据的强大工具。
GLM-4-Plus
发布于8月29日,GLM-4-Plus基座模型,在多个关键指标上实现了大幅提升,尤其是在语言理解能力、指令遵循能力和长文本处理能力方面,通过多种方式构造出了海量高质量数据,并利用 PPO等多项技术,有效提升了模型推理、指令遵循等方面的表现,能够更好地反映人类偏好。
GLM-4-Air
综合性能接近GLM-4,但价格仅为1元100万token,非常适合大规模应用,是性价比很高的版本,具有128k上下文,速度快,价格实惠。
GLM-4-Airx
GLM-4-Air的高性能版本,效果不变,推理速度达到2.6倍,具有8k上下文。
CodeGeeX-4
CodeGeeX是智谱AI旗下的代码生成大模型,2022年9月发布第一代模型,2024年7月5日发布CodeGeeX-4,作为最新一代的CodeGeeX系列模型,大幅提高了代码生成能力,单一模型即可支持代码补全和生成、代码解释器、联网搜索、工具调用、仓库级长代码问答及生成等功能。
GLM-4V
GLM-4V具备视觉理解能力,实现了视觉语言特征的深度融合,支持视觉问答、图像字幕、视觉定位、复杂目标检测等各类图像理解任务。
GLM-4V-Plus
智谱AI发布的新一代图像/视频理解模型,具备卓越的图像理解能力,并具备基于时间感知的视频理解能力,其在图像理解方面表现出色,能够理解并分析复杂的视频内容,同时具备超强的时间感知能力,不仅可以理解网页内容并将其转换为html代码,还能精准描述视频中的动作和场景变化。
阿里云
Qwen-Max
是由阿里云自主研发的大语言模型,它是通义千问系列的一部分,用于理解和分析用户输入的自然语言,其适合处理复杂、多步骤的任务,提供了多个模型版本,包括qwen-max-longcontext,支持长达30,000字的上下文,满足了需要处理长文档或复杂逻辑的任务需求。
Qwen-VL-Max
是阿里开源模型Qwen-VL的升级版,其大幅提升图像相关的推理能力,以及对图中细节和文字的识别、提取和分析能力,并支持百万像素以上的高清分辨率图和各种长宽比的图像,在中文问答、中文文字理解相关的任务上表现出色。
Qwen-Math-Plus
通义千问数学模型是专门用于数学解题的语言模型,致力于解决复杂、具有挑战性的数学问题,其技术原理包括大规模预训练、专用语料库、指令微调、奖励模型、二元信号和PPO优化等,该模型在多个数学基准测试中表现出色,尤其在数学竞赛题目的解答上超越了多个领先的开闭源模型。
腾讯
Hunyuan-Lite
百亿参数规模,Hunyuan-腾讯混元大模型是腾讯全链路自研的万亿参数大模型,Hunyuan-Lite升级为MOE结构,上下文窗口为256k,在NLP、代码、数学、行业等多项评测集上领先众多开源模型。
Hunyuan-Standard
千亿参数规模,采用更优的路由策略,同时缓解了负载均衡和专家趋同的问题,长文方面,大海捞针指标达到99.9%,hunyuan-standard-32K性价比相对更高,在平衡效果、价格的同时,可对实现对长文本输入的处理;hunyuan-standard-256K在长度和效果上进一步突破,极大的扩展了可输入长度。
Hunyuan-Pro
万亿参数规模,当前混元模型中效果最优版本,在各种benchmark上达到绝对领先的水平,复杂指令和推理,具备复杂数学能力,支持functioncall,在多语言翻译、金融法律医疗等领域应用重点优化。
Hunyuan-Code
混元最新代码生成模型,经过200B高质量代码数据增训基座模型,迭代半年高质量SFT数据训练,上下文长窗口长度增大到 8K,五大语言代码生成自动评测指标上位居前列;五大语言10项考量各方面综合代码任务人工高质量评测上,性能处于第一梯队。
Hunyuan-Vision
混元最新多模态模型,支持图片+文本输入生成文本内容,包括图片基础识别、图片内容创作、图片多轮对话、图片知识问答、图片分析推理、图片OCR等能力。
百川
Baichuan3-Turbo
针对企业高频场景优化,效果大幅提升,高性价比,相对于Baichuan2模型,内容创作提升20%,知识问答提升17%,角色扮演能力提升40%。
Baichuan4
百川智能于2024年5月22日发布的最新一代基座大模型,其在通用能力、数学和代码处理能力上都有所提升,在处理知识百科、长文本和创作生成等中文任务时都展现出了优秀的能力,在国内权威大模型评测机构SuperCLUE的评测中,Baichuan4的模型能力排名国内第一,业内水准算第一梯队了。
kimi
Moonshot-v1-8k
Moonshot-v1是Moonshot AI推出的一款千亿参数的语言模型,具备优秀的语义理解、指令遵循和文本生成能力,Moonshot-v1-8k是一个长度为8k的模型,支持8K上下文窗口,适用于生成短文本。
零一万物
Yi-Ligtning
10月16日零一万物正式发布新旗舰模型Yi-Lightning,其理速度有大幅提升,首包时间提升一倍,最高生成速度提速近四成,在多轮对话、数学、代码等多个分榜成绩出众,价格方面也极具优势,已上线Yi大模型开放平台,每百万token仅需0.99元。
Yi-Large
零一万物公司发布于2024年5月13日的一款千亿参数规模的闭源大模型,其主要特点包括超强的文本生成和推理能力,适用于复杂推理、预测和深度内容创作等场景。
Yi-Vision
零一万物发布的开源多模态语言大模型,Yi-Vision基于Yi语言模型开发的,具备高性能图片理解、分析能力,可服务基于图片的聊天、分析等场景。
Deepseek
Deepseek-Chat
DeepSeek是“深度探索”公司开发的模型,基于DeepSeek-V2模型,是一款集成了2千亿参数量的MoE模型的AI技术产品,其特点是经济的训练和高效的推理,支持128K上下文的开源模型,而其对话官网/API则支持32K上下文,提供即刻接入、能力卓越、价格低廉的服务,并且兼容OpenAI API接口,为用户带来丝滑的体验。
Deepseek-Coder
DeepSeek-Coder是一个智能编码辅助工具,能够理解编程问题的描述,并自动生成相关的解决方案或代码片段,其训练数据量高达2T,涵盖87%的代码和13%的自然语言,包括英语和汉语,从1B到33B的不同模型版本,可满足了各种规模项目的需求。
百度
ERNIE-4.0-8k
ERNIE-4.0-8k是百度自研的旗舰级超大规模大语言模型,相较ERNIE3.5实现模型能力全面升级,广泛适用于各领域复杂任务场景;支持自动对接百度搜索插件,保障问答信息时效,支持5K tokens输入+2K tokens输出。
ERNIE-4.0-Turbo
于2024年6月28日发布,是2023年10月推出的 Ernie-4.0模型的升级版,是文心系列最新旗舰版大模型,将输入tokens长度从2K提升至128K,AI生成图像分辨率从512×512提高到1024×1024,在生成速度和效果上都有大幅提升。
阶跃星辰
Step-1V-8k
国内大模型公司阶跃星辰推出的Step-1V是一款千亿参数的多模态大模型,拥有强大的图像理解能力,暂时只开放文本和图像输入,且仅支持文本生成,Step-1V-8k是指上下文长度为8k。
Step-2-16k
2024年7月4日阶跃星辰发布了Step-2模型,这是一个拥有万亿参数的巨型深度学习模型,采用了MoE结构,在数学、逻辑、编程、知识、创作、多轮对话等方面,Step-2的能力体感全面逼近GPT-4,Step-2-16k是指上下文长度为16k。
讯飞
Spark Max
讯飞星火认知大模型是科大讯飞发布的大模型,Spark Max是旗舰级大语言模型,具有千亿级参数,核心能力全面升级,具备更强的数学、中文、代码和多模态能力,适用于数理计算、逻辑推理等对效果有更高要求的业务场景。
Spark Ultra
最强大的大语言模型版本,文本生成、语言理解、知识问答、逻辑推理、数学能力等方面实现超越GPT 4-Turbo,优化联网搜索链路,提供更精准回答。
Spark Lite
轻量级大语言模型,具有更高的响应速度,适用于低算力推理与模型精调等定制化场景,可满足企业产品快速验证的需求。
开源模型
Llama3.2-90B
9月25日正式推出,Meta最先进的模型,擅长常识、长文本生成、多语言翻译、编码、数学和高级推理,还引入了图像推理功能,可以完成图像理解和视觉推理任务。
Llama3.2-11B
非常适合内容创建、对话式人工智能、语言理解和需要视觉推理的企业应用,该模型在文本摘要、情感分析、代码生成和执行指令方面表现出色,并增加了图像推理能力,用例与 90B 版本类似:图像标题、图像文本检索、视觉基础、视觉问题解答和视觉推理,以及文档视觉问题解答。
Qwen2.5-72B
9月19日推出,支持高达128K的上下文长度,可生成最多8K内容,支持超29种语言,基于 18T token 数据预训练,相比Qwen2,Qwen2.5整体性能提升18%以上,拥有更多的知识、更强的编程和数学能力,72B 是足够用于工业级、科研级场景的性能王者。
Qwen2.5-Coder-7B
Qwen2.5-Coder是Code-Specific Qwen大型语言模型的最新系列,是一个专门用于代码生成和编程相关任务的大型语言模型,采用了基于Transformer的架构,并引入了特定的优化技术,如分组查询注意力(GQA)和双块注意力(DCA),以优化推理性能和长文本处理能力。
Llama3.1-405B
Llama3是Meta最新开源的大语言模型,405B适用于合成数据、大语言模型 (LLM) 作为评判者或蒸馏,支持128K token 的上下文长度和 8 种语言,允许使用模型输出来改进其他LLM。
Llama3.1-70B
70B适合大规模 AI 原生应用,拥有70亿个参数,支持8种语言的文本生成,采用优化的Transformer架构,并通过监督式微调和人类反馈强化学习进一步优化,以符合人类对帮助性和安全性的偏好。
Llama3.1-8B
8B适用于需要在多种语言环境下进行自然语言处理和对话系统开发的研究人员和开发者,包含8B大小的版本,支持8种语言,专为多语言对话用例优化。
Llama3-70B
Llama3是Meta于2024年4月18日推出,有8B和70B两个版本,70B拥有700亿个参数,这种复杂性的增加转化为各种NLP任务的增强性能,包括代码生成、创意写作,甚至多态应用程序,它也需要更多的计算资源,需要具有充足内存和GPU能力的强大硬件设置。
Llama3-8B
Llama3-8B型号在性能和资源需求之间取得了平衡,它拥有80亿个参数,提供令人印象深刻的语言理解和生成功能,同时保持相对轻量级,使其适用于具有适度硬件配置的系统。
Mistral-Large-2
2024年7月26日,法国AI初创公司Mistral AI发布了最新模型Mistral-Large-2,拥有1230亿参数,尤其擅长代码和数学推理,上下文窗口128k,支持数十种自然语言以及80+编程语言,特别在MMLU上,其预训练版本更是达到了84.0%的准确率。
Mixtral-8x7B
Mixtral-8x7B是首个开源的MoE大模型,具有8个7B参数的专家和高效的稀疏处理,该模型在每一层都由8个前馈块(即“专家”)组成,通过路由网络为每个令牌选择两个专家进行处理,并将它们的输出结合起来,这种架构允许模型在保持较低计算成本的同时,访问更多的参数。
Gemma-7B
Gemma是谷歌研发的AI大模型,Gemma-7B拥有70亿参数,旨在高效部署和开发,适用于消费级GPU和TPU,在7B参数级别的模型中性能可与最佳模型相媲美,包括Mistral-7B。
Gemma2-9B
Gemma2是谷歌于2024年6月发布的最新开源模型,相比较第一代,Gemma2推理性能更高、效率更高,并在安全性方面取得了重大进步,Gemma2-9B的性能在同类产品中也处于领先地位,超过了Llama3-8B和其他同规模的开源模型。
Gemma2-27B
Gemma2-27B在同类产品中性能最佳,甚至能挑战规模更大的模型,27B模型可用于在单个谷歌Claude TPU主机或NIVIDIA H100 GPU上以全精度高效运行推理,从而在保持高性能的同时大幅降低成本。
Command R+
Cohere公司最新推出的模型,这是Command R系列中最强大的模型,总计拥有1040亿个参数,其独特之处在于其强大的生成能力和先进的检索功能,可以让模型根据给定的上下文信息,从外部知识源中检索相关内容,并将其融合到生成的响应中,有效缓解模型的”幻觉”问题。
Command R
Command-R拥有35B的模型参数,提供了强大的语言理解和生成能力,模型支持高达128K的上下文窗口,大大超越了行业标准,使其能够处理更复杂的文本和生成更连贯的内容。
Qwen2-72B
于2024年6月7日发布,是阿里云研发的通义千问大模型系列之一,72B指令微调版模型,还增大了上下文长度支持,最高可达128k token,其具有大规模高质量训练语料、强大的性能、覆盖更全面的词表等特点。
Qwen2-7B
Qwen2是阿里通义推出的新一代多语言预训练模型,包含0.5B、1.5B、7B、57B-A14B和72B共5个尺寸,其中Qwen2-7B支持更长的上下文长度,最高可达128K tokens,在中文和英语的基础上,新增27种语言的高质量训练数据。
Llama-3.1-nemotron
是英伟达NVIDIA开发的一系列大型语言模型,基于Llama-3.1-70B开发而成,它采用了一种新颖的神经架构搜索(NAS)方法,从而建立了一个高度准确和高效的模型。在高工作负荷下,该模型只需一个英伟达H100 GPU 即可运行,因此更易于使用,也更经济实惠。
其他模型
farui-plus
由阿里云推出的一个法律大模型产品,它基于通义千问大模型,经过法律行业的数据和知识专门训练,具有法律智能对话、法律文书生成、法律知识检索、辅助案情分析、法律文本阅读和解析、合同条款审查等功能。
XuanYuan-70B
轩辕是国内首个开源的千亿级中文对话大模型,同时也是首个针对中文金融领域优化的千亿级开源对话大模型,轩辕70B(度小满中文金融对话大模型)是由度小满金融开发的中文金融对话大模型,针对金融场景中的长文本业务,它将上下文长度扩展到了8k和16k,在保持中英文通用能力的同时,显著提高了金融理解能力。
ChatLaw
由北京大学信息工程学院袁粒课题组与北大-兔展AIGC联合实验室联合发布的中文法律大模型,于2023年7月发布,其是基于各种中文法律条文、实际案例、判决条文所训练出来的法律大模型,可借助 AI实现法律合同撰写、案例介绍、条款讲解、司法问题咨询等场景。
Qwen2-Math-72B
阿里巴巴于8月8日再次开源了Qwen2-Math系列模型,这是一个专注于数学推理能力的模型,在Math上的评测结果表明,Qwen2-Math-72B超越了最先进的模型,包括GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro和Llama-3.1-405B。
grok-2
发布于2024年8月13日,是xAI公司推出的一款先进的人工智能语言模型,包括Grok-2和Grok-2 mini两个版本,具有聊天、编码和推理等功能,该模型拥有3140亿个参数,是迄今为止参数量最大的开源模型,这使得它在处理复杂任务和生成高质量文本方面具备了更强的能力。