大家好,我是男秀。
最近,开智社群开了一门「零基础 AI 大模型研发训练营」课程。作为一名有着多年经验的 Python 工程师兼开智铁粉,这波羊毛……啊不,这门硬核课程必须第一时间加入。
经过“七七四十九天”的疯狂折磨,今天终于可以正式宣告:我亲手微调并上线了自己的第一个小模型!
一
2026 年初 OpenClaw 爆火,之后又出现了 Hermes。但只要你深入用过就会发现,这些项目本质上都是在代码层面为 AI 搭建外部环境。
AI 生态工具变化太快了,几个月甚至几周就会迭代一轮。天天去追这些随时可能被替代的脚手架。不如把精力收回来,去学习未来三到五年都不会变的底层知识——而大模型研发与微调的底层逻辑,恰恰就属于这一类。
费曼说过:“我不能创造的东西,我就不理解。”对大模型祛魅的最好方式,就是亲自去创造它。 这也是我深度参与大模型训练营的初衷。
二
开智的课程一如既往地保持着高信息密度的传统,也有很多必须动手的作业。
作为打工人,我的时间几乎全部分散在上班工作、照顾家庭等等日常琐事中,留给课程学习的时间极少。如果没有 AI 的配合,单靠肉身我几乎完成不了这些作业。
不过,成年人社会没有标准答题操作,我有我自己的破局之道:我的本地电脑本身接入了一块 NVIDIA RTX 4060 显卡。为了充分利用这个显卡,我在本地电脑部署了一个国产的 OpenClaw工具,然后将其对接到了飞书,加上deepseek最近发布了v4-pro版本,成本和效果达到了预期。
通过国产OpenClaw、飞书和4060显卡,我拉起了一套自动化训练流,直接通过飞书发送命令给OpenClaw工具,让它帮我执行:于是出现了这样的画风:我在公司上班的时候,OpenClaw 在后台跑训练;我晚上睡觉的时候,OpenClaw 还在跑训练。
并且每次睡觉前我给飞书发任务时,我老婆还吐槽我是个资本家+周扒皮,哈哈。
另外,相比于需要盯着余额的云平台,使用本地显卡最大的好处,是拥有了“大胆试错”的安全感。别人是大胆假设小心求证,我是大胆假设大胆求证。 这次数据集微调出来的效果不行,大不了就重新再训一遍!
三
工程这块,懂的不难,不懂才难。只有真正上手做过,才会形成自己的“行动知识”。
正如课程讲师提到,微调模型最重要的还是数据集。想要模型效果符合预期,至少需要 3000 条高质量的数据集。
在构建这 3000 多条数据的过程中,我实践下来最重要的一个心得就是:蒸馏大于爬取。 利用大模型的能力蒸馏出来的数据,质量远比直接去网上抓取的数据要高得多。
当然,工程上也有小技巧。盲目堆数据很容易浪费精力,我参考了一些做法:先精选 30 条核心的”黄金数据集”进行冒烟测试,验证方向没问题后,再扩充到 300 条微调,最后才逐步往上增加。
到这一步,前面提到的”本地显卡放心大胆试错”的心理优势就彻底闭环了——正是因为有 4060 在后面顶着,不计成本,我才可以放开手脚去迭代数据。一次效果不行?删掉重训。方向跑偏了?砍掉一半再试。这是一种大胆试错的安全感,与在云平台盯着余额跑训练的心理是不一样的。
四
怎么构建高质量的数据集?技术之外,最核心的其实是熟悉业务领域知识。
在这次微调我的“咖啡师小模型”时,我遇到的最大难点,不是技术知识不足,而是我根本不知道一个真实的吧台咖啡师,到底需要哪些核心知识。
在模型早期的内测评估阶段,因为我对业务不够懂,只能全靠大模型的能力去进行数据蒸馏。小模型是能够微调出来了,但是我很难评估它的准确性,所以我让更厉害的模型去评估的时候,总是会出现一些冲煮参数不准确的硬伤。
比如模型会把冲煮水温写成”245°C”——水都烧干了。这种低级错误,不靠懂咖啡的人来纠正是发现不了的。
这一点让我对微调模型有了更深的体会:大模型可以让不懂业务的人,轻易达到60分或者70分,但是想要达到90分甚至更高的分数,还是需要业务专家的参与。
五
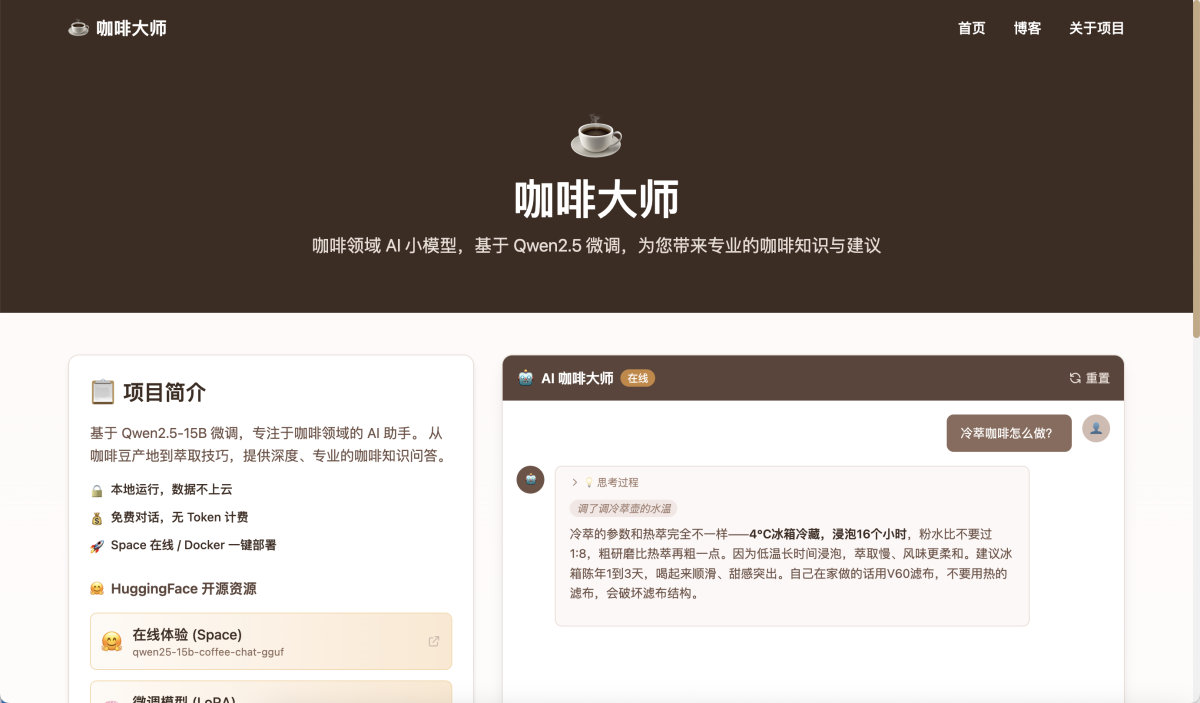
我最终微调出来的,是一个“吧台咖啡师”的垂直场景模型。
用户进入网站,就好像访问了一家真实的咖啡店。在吧台里,有一位咖啡师在随时和你对话。
为了还原这种场景感,我特地调整了语气风格:
- 去百科化: 它的输出不会像 ChatGPT 那样,一开口就是一股标准、冰冷、充满教科书感的 AI 味。
- 带点小情绪小动作: 我在数据集里特意加了一点咖啡师的小动作和小情绪。比如每次对话开头可能会有“调了调冷萃壶的水温”这样的小动作。
- 压缩思考窗口:小模型的”脑容量”有限。我让它只记关键词(比如”深烘|水温|85-90°C”),不做长篇推理。用最少的信息锚定正确的答案。
体验地址已经上线,欢迎大家去我的“吧台”坐坐:
🔗 体验地址:https://coffee-master.zeabur.app
六
训练出自己的小模型之后,我一直在思考一个问题:大模型能替代 Agent 吗?
这次完整地走完微调、量化到部署的一整套流程后,我找到了答案:哪怕把小模型微调得炉火纯青,依然替代不了 Agent 开发。
因为大模型最擅长的是“推理”,而不是“搞琐事”。
像最基础的会话 Session 状态保持、复杂的业务流控制(Workflow)、以及特定敏感话题的拦截与拒绝回答功能,这些工程层面的脏活累活,天然就不是大模型擅长的舞台。大刀阔斧的业务框架,必须由 Agent 来死死守住。
最近我看到一篇风向标新闻:一家团队通过「后训练 + Agent」的深度结合,拿下了特定垂直领域的最高分。
结合这次微调经历,我预测:未来的技术大趋势,必然是后训练与 Agent 开发的深度结合。
未来计划是对我的小模型加上小agent,模型负责”聊天语气”和”咖啡知识”,Agent 负责拦截敏感问题、管理会话状态等——各司其职。
七
课程结尾有一句金句:“当你学会创作大模型,你就不再是 AI 的旁观者,而是成为 AI 的掌控者。”
从最开始学习底层理论、拆解 Token,到后来亲手搞定准备数据、预训练、后训练、量化以及最终的部署,我完整地走了一遍大模型研发的全流程。这种把控感,让我真正拥有了创作属于自己的小模型作品的能力。
按照玩游戏的成就体系来看:
- 今日成就已达成: 成功训练并上线自己的第一个大模型。
- 主线任务进行中: 后面还要再多折腾几次,通过高频迭代让模型成为我真正的技术代表作。
期待早日通关,拿下「模型家」这个称号。